Overview
A version 2 HFile is structured as follows:
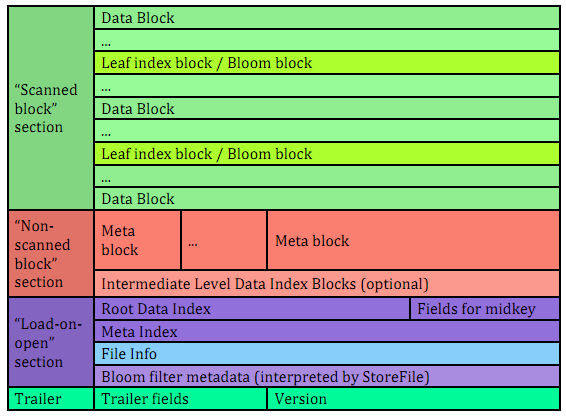
Unified version 2 block format
在版本2中,数据部分中的每个块都包含以下字段:
(1) 8字节字节序列,用于标识块类型,这个字节序列相当于版本1的”magic records”。支持的块类型包括:
- DATA:数据块
- LEAF_INDEX:多级索引中的叶子节点
- BLOOM_CHUNK:bloom filter
- META:元数据块,版本2中不再包含bloom filter
- INTERMEDIATE_INDEX:多级索引中的中间节点
- ROOT_INDEX:多级索引的根节点
- FILE_INFO:元数据的少量的kv map
- BLOOM_META:bloom filter的元数据块
- TRAILER:固定大小,记录其他各个快偏移量
- INDEX_V1:该类型仅仅用于版本1的block
(2) 块数据压缩之后的大小,不包括头信息(int)
当顺序读HFile数据的时候,可以用来跳过当前数据块
(3) 数据块压缩之前的大小,不包括头信息(int)
如果压缩算法配置为none,那么该大小和上个字段相同
(4) 相同类型的上一个块的偏移量(long)
可以用来查找上一个数据块或者索引块
(5) 压缩之后的数据(如果压缩算法为none,实际上是压缩之前的数据)
上面的块格式用于以下HFile部分:
- 扫描块部分。该部分被如此命名是因为它包含所有数据块,当HFile按顺序扫描时需要读取,还包含叶子节点索引块和bloom块
- 非扫描块部分。该部分也满足统一的v2格式,但在进行顺序扫描时不需要读取它。该部分包含元数据块和中间节点索引块
Block index in version 2
HFile版本2中有三种类型的索引块,以两种不同的格式(root和非root)存储:
- 数据块索引——版本2中是多级索引,包括:
- 根索引,(stored in the data block index section of the file)
- 中间节点索引,可选的,只有存在叶级别块时才能存在中间级别(stored in the non%root format in the data index section of the file)
- 叶子节点索引,可选的,采用non-root索引格式,和数据块保存在一起
- 元数据索引——版本2中仅采用root索引的格式,(stored in the meta index section of the file)
- bloom索引——版本2中仅采用root索引的格式,(stored in the “load-on-open” section as part of Bloom filter metadata.)
上面提到的保存位置可以在文章开始的图片中清楚的看到。
Root block index format in version 2
该格式应用于:
- 版本2的数据块的根索引
- 整个元数据索引和bloom的索引,两者都是一级索引
版本2的根索引是以下部分组成的序列,跟版本1基本相似,但是(storing on-disk size instead of uncompressed size.)保存的是磁盘上占用的大小而不是压缩之前的大小
- Offset (long)
offset可能指向数据块或者下一级索引所在的块
- 磁盘上的大小(int)
- key,指向的block的第一个key(序列化的字节数组)
- key(VInt)
- key的字节
版本2的数据块如果只有一级索引,那么也就只有根索引,要读取版本2的根索引,需要知道根索引中entry个数。对于数据索引和元数据索引来说,entry的个数保存在trailer中,对于bloom索引来说,保存在整合的Bloom filter metadata中。
对于多级索引来说,在根索引中除了保存上面的信息之外,还有下面的field:
- 中间位置的叶子节点索引块的offset
- 中间位置的叶子节点索引占用的磁盘空间
- 中间位置的叶子节点索引的mid-key
上述的附加字段用于在HFile拆分过程中,有效的获取mid-key,如果HFile中有n个快,mid-key被定义为第(n – 1) / 2个块的第一个key。这个定义跟HFile版本1的定义相同,通常来说是合理的,因为块基本上有相同的大小,但是没有对单个key/value的大小进行评估。
当写入一个HFile的时候,每个叶子节点索引所指向的数据块的总数会一直被记录。当写操作结束,并且叶子节点索引对应的数据块的数量被最终确定,此时哪个叶子节点对应的数据块包含mid-key能够被确定,并且上述的字段也能被计算出来。当读取一个HFile并且查询mid-key的时候,会去获取中间节点索引的数据块(可能已经缓存起来了),然后从叶子节点数据块的适当位置拿到mid-key的值。
Non-root block index format in version 2
该格式应用于多级索引中的中间节点索引和叶子节点索引。每个non-root索引块的结构如下:
- numEntries:entry的个数
- entryOffsets:Non-root block index中各个entry所在的块的offset形成的索引,用于对Non-root block index的entry进行快速的二分查找(共numEntries + 1 个int值)。最后一个值是所有的entry的总长度。例如,在索引中有三个entry,大小分别为60, 80, 50,那么entry的offset形成的索引为{0, 60, 140, 190}
- Entries:每个entry包括:
- 该entry对应的块的偏移量(long)
- 指向的块的大小(int)
- Key,Key的长度可以通过上面的entryOffsets来计算(这个不知道啥意思。。。)
Bloom filters metadata in version 2
与版本1相比,版本2中的bloom Filter保存在the load-on-open section部分,用于快速构建
一个复合的bloom filter包含:
- 版本号,对应3 (int),之前的DynamicByteBloomFilter的版本是2
- 所有bloom filter的字节总数(long)
- hash函数的数量(int)
- hash函数的类型(int)
- 插入bloom filter的key的总量(long)
- bloom filter中key的最大总量
- 块的数量(int)
- bloom filter的key比较器的类,使用Bytes.writeByteArray存储的UTF-8编码的字符串
- bloom块的索引采用版本2中root index的格式
File Info format in versions 1 and 2
file info块是序列化的hashmap(本质上是字节数组到字节数组的映射),具有下列的key,storeFile级别的逻辑的key添加到file info中。
- hfile.LASTKEY:hfile的最后一个key(byte array)
- hfile.AVG_KEY_LEN:hfile的key长度的平均值(int)
- hfile.AVG_VALUE_LEN:hfile的值的长度的平均值(int)
文件信息格式在版本2中没有变化。但是,我们将文件信息移动到文件的最后一部分,可以在打开HFile时将其加载。版本2中,我们不再将比较器保存在file info中。而是保存在固定的trailer中。因为我们在解析hfile的the load-on-open section部分的时候就需要知道比较器。
Fixed file trailer format differences between versions 1 and 2
下表中比较了版本1和版本2的固定的文件trailer。需要注意的是,trailer的大小在版本1和2中是不同的,“固定”仅仅是针对版本内部。对于两个版本来说,version字段都是保存在trailer最后的四字节。
简单来说,就是保存上面讲到的各个block在磁盘中的offset,以便最开始加载Hfile的时候,读取相应的block。
